AVG biedt groeikansen

Door de overvloedige berichtgeving in de media weet u waarschijnlijk dat de General Data Protection Regulation (GDPR) ofwel Algemene Verordening Gegevensbescherming (AVG) van kracht wordt. In veel van die berichtgeving worden horrorscenario’s geschetst: Er zouden vergaande maatregelen nodig zijn om torenhoge boetes te voorkomen. Hoe de nieuwe wetgeving uitpakt, valt nog te bezien. Feit is wel dat de AVG meer van u vraagt dan de oude privacy regels.
Waar voorgaande privacy regelgeving vooral gebaseerd was op het recht van individuen met rust gelaten te worden, vereisen de nieuwe regels dat organisaties zich aan de volledig wetgeving houden. Dit betekent dat organisaties op dit gebied nu actief moeten optreden. Ze moeten in control zijn over persoonsgegevens. Met andere woorden: Vanaf mei dit jaar is Privacy by Design of Privacy by Default een wettelijk vereiste.
En juist hierin ligt een heel duidelijke relatie met Data Governance. Data Governance zorgt ervoor dat alle data gemanaged wordt. In het veel gebruikte raamwerk: The Data Management Body of Knowledge (DMBOK) van the Data Management Association International (DAMA) stuurt Data Governance alle Data Management kennisgebieden aan. Als we deze kennisgebieden naast de uitgangspunten van de AVG leggen wordt duidelijk dat aandacht voor Data Governance inderdaad een eerste belangrijke stap is in de richting van compliancy.
De AVG heeft de volgende uitganspunten:
- Persoonsgegevens mogen alleen voor wettelijk toegestane doelen, op een eerlijke, transparante manier verwerkt worden.
- De doelen waarvoor persoonsgegevens verzameld worden, moeten expliciet omschreven zijn. De gegevens mogen alleen hiervoor verwerkt worden en niet voor doelen gebruikt worden die hier niet mee overeenkomen.
- Persoonsgegevens moeten relevant zijn voor en beperkt blijven tot het doel waarvoor ze verzameld worden.
- Persoonsgegevens moeten correct zijn. Organisaties moeten er alles aan doen om ze up-to-date te houden.
- Persoonsgegevens mogen niet langer dan nodig is, opgeslagen en verwerkt worden.
- Persoonsgegevens moeten beschermd worden tegen oneigenlijk gebruik door middel van technische en organisatorische maatregelen.
- Iedereen die met persoonsgegevens in de weer is, is er verantwoordelijk voor dat deze regels worden nageleefd. Compliance moet actief aantoonbaar zijn.
In veel van deze uitgangspunten speelt transparantie een hoofdrol. Wij komen bij veel organisaties waarin de datahuishouding in de loop van de tijd organisch gegroeid is. Veel expertise bevindt zich in de hoofden van de medewerkers maar ligt uiteindelijk onvoldoende vast in documenten. Met het oog op transparantie is het hebben en onderhouden van een datamodel een eerste vereiste.
Hierin wordt in relatie tot de doelen van een organisatie duidelijk over welke entiteiten (klanten, prospects, medewerkers, leveranciers,…) data verzameld wordt. In Data Lineage documenten wordt vervolgens duidelijk hoe deze data door aderen van de organisatie stroomt.
Dergelijke blauwdrukken vormen het hart van de Data Architectuur. Deze blauwdrukken zorgen voor een gemeenschappelijk begrip van data en datastromen. Ze kunnen onder andere gebruikt worden om de organisatie te stroomlijnen en risico’s in te schatten. Zo wordt duidelijk dat er wellicht data in omloop is waar de organisatie niets mee doet.
Naast Data Modeling en Data Architectuur is ook het kennisgebied van Metadata van belang. Door Business Metadata vast te houden is voor iedereen duidelijk waarom we bepaalde data verwerken en vast houden. Technische en Operationele Metadata geven per record weer hoe we met data omgaan. Metadata maakt AVG compliancy eenvoudig aantoonbaar.
Zoals hierboven aangegeven, moeten we er verder alles aan doen om persoonsgegevens up-to-date te houden. Daarmee komen we op het kennisgebied van Data Quality uit de DAMA-DMBOK. Door Data Quality op peil te houden, blijft data “Fit for Use”. Een belangrijk aspect hierbij is dat er één waarheid rondom persoonsgegevens ontstaat, ook wel Golden Record, 360 Graden Klantbeeld Single Point of Truth genoemd. Hiermee houden de kennisgebieden van Data Integration en Master & Reference Data zich bezig. Daarmee kan de hoeveelheid data die in verschillende afdelingen van de organisatie wordt opgeslagen vaak drastisch beperkt worden, wat de kans op fouten en inefficiency aanzienlijk beperkt.
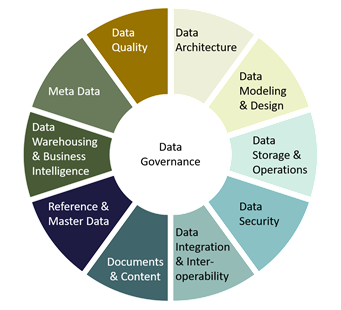 Het raamwerk van DAMA-DMBOK
Het raamwerk van DAMA-DMBOK
Tot slot komt ook het veiligheidsaspect uitvoerig terug in het DAMA raamwerk. Dit is terug te vinden in de kennisgebieden Data Storage en Data Security.
Het zal duidelijk zijn dat organisaties die actief zijn in Data Governance een enorme voorsprong hebben als het gaat om de implementatie van de AVG. De grote vraag blijft echter of dat in dit kader van de nieuwe wetgeving voldoende is. Er is immers nog geen jurisprudentie op dit gebied voorhanden. Om het zekere voor het onzekere te nemen voeren veel organisaties de Privacy Deep Scan uit. Dit is dè standaard voor Privacy Maturity en ontwikkeld door verschillende privacy experts.
De Privacy Deep Scan is een objectieve, volledig dekkende meting op meer dan 1600 punten, inclusief een volledige ICT Security scan, gebaseerd op ISO27001. De scan resulteert niet alleen in een uitgebreid rapport maar voorziet vooral in een aantal concrete maatregelen. Deze zijn gebaseerd op uw ambitieniveau en geven helder richting aan de te nemen acties. De Privacy Deep Scan is gericht op continu verbeteren van de organisatie, de operatie en data specifieke aspecten. U toont er mee aan een zeer gedegen start te hebben gemaakt in het kader van de AVG.
Maar er is meer… De Privacy Deep Scan en de daaruit voortvloeiende acties op het gebied van Data Governance zullen uw organisatie versterken. U voorkomt kostbare fouten maar misschien nog wel belangrijker: U neemt betere operationele en strategische beslissingen als u over goede data beschikt.
Goede data is Fit for Use. En wat dat betekent, bepalen business en IT in overleg. De blauwdrukken waarover u in het kader van AVG moet beschikken, zijn het communicatiemiddel om binnen de eigen organisatie tot overeenstemming te komen. We zouden de AVG ook meer in dat licht kunnen beschouwen. We grijpen de wetgeving aan om onze datahuishouding op orde te krijgen om daarmee meer waarde uit onze data te halen. Want ook binnen de nieuwe wetgeving kan er nog heel veel: Als u daar maar transparant over bent.
Interesse in de Privacy Deep Scan of de DAMA-DMBOK training? Neem contact op met Data Kitchen: info@datakitchen.nl of bel Mark Leijdekker: +31 6 552 01 294
Contact
Data Kitchen
Rouwkooplaan 5
2251 AP Voorschoten
Meer weten?
Bel Astrid Rosdorff:
+31 (06) 515 26 880
![]()
Contact informatie
Data Kitchen
Rouwkooplaan 5
2251 AP Voorschoten
Meer weten?
Bel Astrid Rosdorff:
+31 (06) 515 26 880
Website door: 